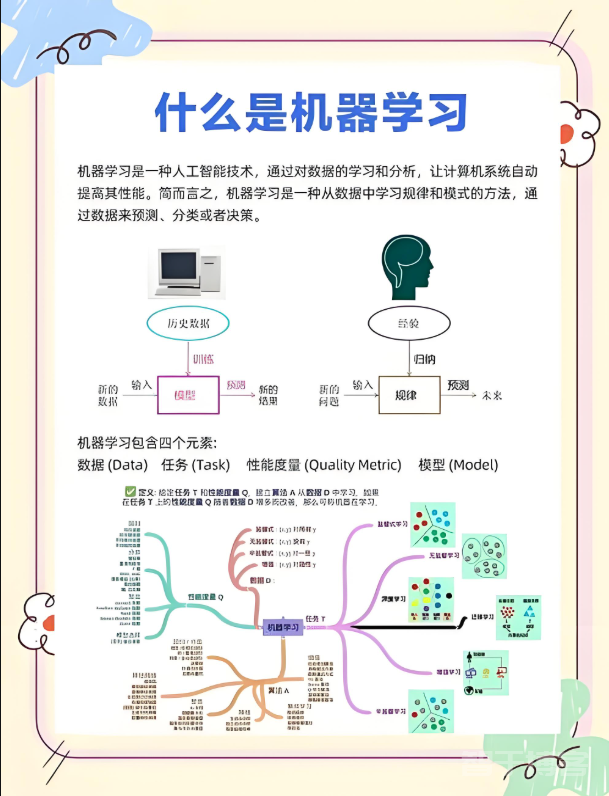
机器学习是通过数据驱动让计算机从经验(数据)中自动学习规律,无需显式编程即可完成任务的技术。其核心概念可分为三大类:基础概念、算法类型、模型评估指标。
特征(Feature):描述数据的 “属性”,是模型学习的输入。例如判断 “是否为垃圾邮件” 时,“邮件包含‘免费’次数”“发件人是否陌生” 就是特征。
标签(Label):数据的 “结果” 或 “目标”,是模型需要预测的输出。例如垃圾邮件判断中,“是垃圾邮件(1)” 或 “不是垃圾邮件(0)” 就是标签。
数据集划分:为避免模型 “作弊”,需将数据分为三类:
训练集(Training Set):用于模型学习规律,占比通常 60%-80%;
验证集(Validation Set):用于调整模型参数(如超参数),避免过拟合,占比 10%-20%;
测试集(Test Set):模拟真实场景,评估模型最终泛化能力,占比 10%-20%。
泛化能力(Generalization):模型对 “未见过的新数据” 的预测能力,是机器学习的核心目标(好的模型需 “举一反三”,而非 “死记硬背”)。
过拟合(Overfitting):模型过度学习训练集细节(包括噪声),导致训练集表现极好,但测试集表现差。例如学生死记硬背题库,考试遇到新题就不会。
欠拟合(Underfitting):模型未学到训练集的核心规律,训练集和测试集表现都差。例如学生未理解知识点,连题库题都做不对。
根据数据是否有标签、学习方式的不同,机器学习算法可分为四大类:
不同任务需用不同指标衡量模型性能,核心指标如下:
分类任务(如垃圾邮件识别、疾病诊断):
准确率(Accuracy):预测正确的样本占总样本的比例(适用于数据平衡场景);
精确率(Precision):预测为正类的样本中,实际为正类的比例(减少 “误判”);
召回率(Recall):实际为正类的样本中,被预测为正类的比例(减少 “漏判”,如癌症诊断需高召回率);
F1 分数:Precision 和 Recall 的调和平均数,平衡两者。
回归任务(如房价预测、气温预测):
平均绝对误差(MAE):预测值与真实值的绝对差的平均值(直观反映误差大小);
均方误差(MSE):预测值与真实值的平方差的平均值(惩罚大误差,如金融预测);
决定系数(R²):衡量模型解释数据变异的能力,取值 0-1,越接近 1 越好。
聚类任务(如用户分群):

